Research
Group highlights
This is a highlight reel of some representative work. You can see more publications on group members’ individual websites, listed on the Team page.

We carry out a data archaeology to infer books that are known to ChatGPT and GPT-4, finding that OpenAI models have memorized a wide collection of copyrighted materials, and that the degree of memorization is tied to the frequency with which passages of those books appear on the web. The ability of these models to memorize an unknown set of books complicates assessments of measurement validity for cultural analytics by contaminating test data; we show that models perform much better on memorized books than on non- memorized books for downstream tasks. We argue that this supports a case for open models whose training data is known.
Kent K. Chang, Mackenzie Cramer, Sandeep Soni and David Bamman
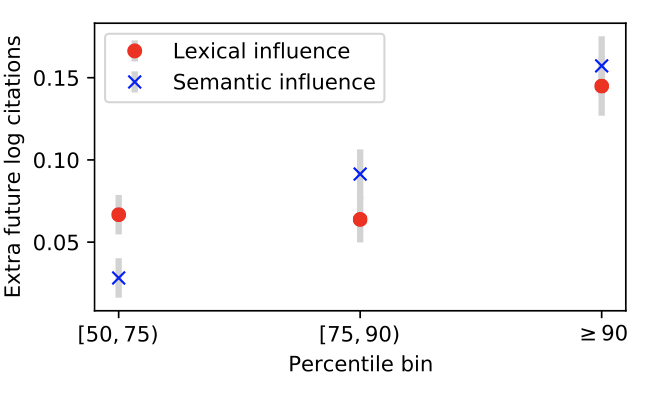
Citation count is an imperfect proxy of linguistic influence of research publications. We propose a novel method to quantify linguistic influence in timestamped document collections, first identifying lexical and semantic changes using contextual embeddings and word frequencies, and second, aggregating information about these changes into per-document influence scores by estimating a high-dimensional Hawkes process with a low-rank parameter matrix. This measure of linguistic influence is predictive of future citations: the estimate of linguistic influence from the two years after a paper’s publication is correlated with and predictive of its citation count in the following three years.
Sandeep Soni, David Bamman and Jacob Eisenstein
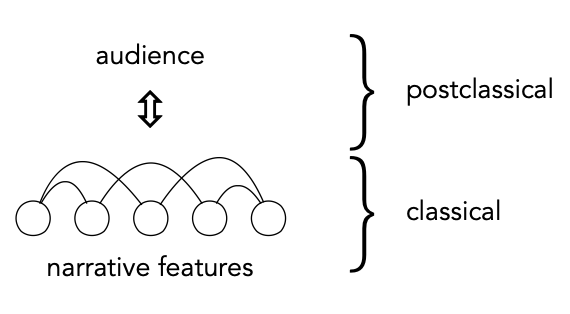
In this position paper, we introduce the dominant theoretical frameworks on narrative to the NLP community, situate current research in NLP within distinct narratological traditions, and argue that linking computational work in NLP to theory opens up a range of new empirical questions that would both help advance our understanding of narrative and open up new practical applications.
Andrew Piper, Richard So and David Bamman